and here is a legend (explanations found later in this document):
Last modified: 9 Nov 2021
A Virtual Computing Laboratory (VCL) is a collection of managed, reconfigurable computers and an efficient storage system for them. Using the VCL web interface, users reserve time for a computing environment they or an instructor specify, and the VCL management software provides that environment for them at or near the time of the reservation. Our VCL was inspired by the North Carolina State University VCL, which is now open-sourced as Apache VCL.
A computing environment consists of compute nodes, a network to connect them and software to run on them.
The "computing machines" are either a real physical machine or a virtual machine (VM) running on a real machine. There can be many virtual machines running as "guests" on a real "host" machine, using hypervisor software.
A VCL can provide predefined machines or allow creation of user-defined machines for faculty and students. They might need the machines for in-class assignments, out of class assignments/projects or research projects. Lab staff or faculty can create pre-defined virtual machines with specific software installed and configured on them, or a virtual machine can be created by the user for any academic purpose. Given the proper hardware support, a real machine (also known as "bare metal", if nothing is installed on it) can be used to satisfy the needs of the user.
The VCL management node manages the loading or storing of computing environments. Disk images or virtual machine images are stored in a large, parallel file system (called a storage cloud) and are loaded onto the compute nodes' local disk as needed. After the user's reserved time has expired, the management node suspends or shuts down the computing environment and saves it to the storage cloud to preserve any changes.
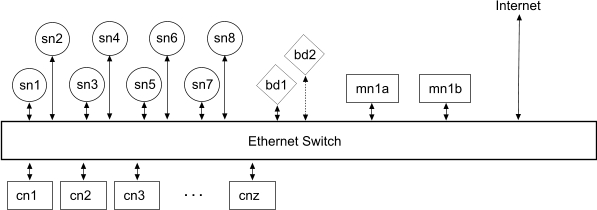
Here is a picture of what a VCL looks like:
and here is a legend (explanations found later in this document):
A storage cloud is a collection of networked computers called storage nodes that are dedicated to storing and loading huge files (from 600MB to about 10GB apiece), reflecting either CD/DVD ISO images, complete VMs images or disk images. The cloud uses multiple computers to eliminate bottlenecking to one computer, as well as to provide some reliability through redundancy of data. Storage software glues the local filesystems together to make them appear as one filesystem.
Storage performance is limited by the local (i.e., same room) networking fabric The fabric is 1Gb ethernet using TCP/IP (until we can afford 10+Gb ethernet, InfiniBand, or other high-performance equipment). Initial measurements indicate about 80MB/sec read and 50MB write between one client and one server, with large blocksizes but without tuning or striping (or exploiting redundancy for high availability).
A storage node is a simple computer with a lot of disk space and a 1Gb NIC. Specifically:
| VCL Number | Machine Type | CPU Make/Model | RAM | Disk | IP Range | Quantity |
|---|---|---|---|---|---|---|
| 1 (CP 206N, inactive) | AsRock A780GMH, micro-atx | Athlon 64 X2 Brisbane 2.6Ghz AM2 45W | 2GBx2 PC2-5300 | Barracuda 7200.12 500GB SATA II 16MB | 10.0.254.1 to 10.0.254.8 | 8 |
| 2 (inactive) | Gigabyte GA-D525TUD, mini-itx | Intel Atom D525 1.8Ghz | 2GB DDR3 1333/PC3 10666 | Spinpoint F3 1TB 7200 RPM SATA 3Gb/s | 10.1.254.1 to 10.1.254.8 | 8 |
| 3 (DOU 110) | Gigabyte GA-D525TUD, mini-itx | Intel Atom D525 1.8Ghz | 2GB DDR3 1333/PC3 10666 | Spinpoint F3 1TB 7200 RPM SATA 3Gb/s | 10.2.254.1 to 10.2.254.12 | 12 |
| 4 (CP 206E/F) | none | n/a | n/a | n/a | n/a | n/a |
| 5 (SCI 113) | none | n/a | n/a | n/a | n/a | n/a |
| 6 (CP 206H) | none | n/a | n/a | n/a | n/a | n/a |
| 7 (CP 206I) | none | n/a | n/a | n/a | n/a | n/a |
| 8 (CP 206E) | none | n/a | n/a | n/a | n/a | n/a |
A collection of storage nodes constitutes a "storage cloud". There is one storage cloud per VCL. One cloud per VCL helps us maintain performance by keeping storage nodes, management nodes and compute nodes on one switch. These are the storage clouds per VCL:
The storage nodes are nearly identically configured; the exception is the name and IP address of the node. Each node runs a Linux 64-bit OS (as of Dec 2014, Fedora 19 x86_64) because massive file systems require 64-bit processing. Running the node on top of a hypervisor was considered, but since most hypervisors require specific versions of a processor for virtualization support (viz., segmentation) in order to run 64-bit guests, and some of the original nodes' CPUs did not have that support. In addition, we weren't sure if virtualization would cause significant performance problems.
Storage nodes are clustered for redundancy, availability and performance. For example, storage node 1 (sn1) replicates its data to node 2 (sn2), and vice versa. Round-robin DNS and special timeout settings allow a storage client (usually, a compute node) to point to the cluster and get the IP address of either a random node in the cluster (i.e., either sn1 or sn2), or the live node if one of them is down -- unintentionally, or for maintenance.
Storage on a node is divided into two areas (partitions): a read-only partition, and a read-write partition. The read-only partition holds images (ISO, VM and disk) that we don't want users to change, while the read-write partition is where changed VM and disk images are loaded from or stored to. Ideally, the only direct access the user has is to the read-only partition so that images can be referenced or copied to the local hard drive of a compute node. Most of the time, those images should only be ISO images, as the management node controls loading and storing of VM and disk images.
The storage management software is glusterfs. It runs on both the client and the server. The server daemon ("glusterfsd") handles storage requests from the client, such as creating a file or finding a directory. It virtualizes a host file system, or directory on a file system, and presents it as one storage "brick" in the cloud. Many servers serving bricks make up a cloud if the clients look at the bricks as an aggregate. Clients access directories in the the storage cloud by mounting the cloud and issuing normal file operations to it, so the cloud appears to them as just another mounted file system or directory.
GlusterFS can be configured fairly easily with replication, performance enhancements and/or striping. Most of the configuration is present on the client side. For example, replication is seen as a client sending write requests to two (or more) remote servers -- client-side replication -- vs. a remote server performing the write request to its local disk and sending a write request to another server -- server-side replication. With server-side replication, the client is attached to one server, so if that server fails, the client will unsuccessfully attempt to send requests to the failed server instead of sending them to the other server; the client does not know anything about the other server. With client-side replication, the client can detect that the first server is down and send only to the second server, because it knows both servers. With round-robin DNS and client-side timeouts, however, one can configure a reasonable server-side replication with failover, so the clients won't be aware of the replication and also won't be stopped by one failed server.
Ideally, storage requests would be evenly distributed across all storage nodes for maximum throughput. However, this ideal would be difficult to reach because when the separate bricks are aggregated to avoid the single-server bottleneck, you also lose control of which server can serve which file -- it must be the server that holds the file. If one is unlucky, all of the file requests are sent to the same server. Replication can help when the requests are to read data, since either one of the two servers (in our case -- there could be more) can be chosen -- if client-side replication is used. But in the write request case -- the case where one could really use some help since single writes are so slow -- it's much worse, since two write requests must be done fairly simultaneously. Multiple clients trying to write to the same storage node can bring the system to its knees in the worst cases.
We can lessen the chance that many requests go to the same storage node by:
The original design of VCL 1 (with 20 compute nodes, since reduced to 10) called for 16 storage nodes to provide an almost two to one ratio of compute to storage nodes. Cost and switch port space limitations cut that back to eight storage nodes. When considering the cost in time to the users of losing gigabytes worth of images and hours of time, reliability through redundancy was considered very important, and now we are down to four storage nodes. Since there are less nodes than expected and we anticipate one user per four cores (at one VM per core), then this is about five users per storage node, on average. Since a 500GB storage node has about 300GB of usable disk space for read/write, and we expect heavy users to have about 25GB of storage, there could be as many as 12 users per storage node. Storage nodes with 1TB disks will allow more users, but many image sizes are now 2-3 times larger than when VCL 1 was designed, so we expect about the same number of users.
Unfortunately, we can't easily prevent those problematic 12 users from accessing the same disk. It may be possible to consider the disk space to be a resource that is consumed if n users are using it, such that the node can't be reserved if the storage space is in use by its maximum number of users. That would have to be a feature of the reservations system and the management system.
Compute nodes are the reconfigurable real machines that are loaded with a disk image onto "bare metal", or already have a disk image loaded and have VMs loaded into the hypervisor or OS's file system.
Here is the inventory of real machines, per VCL:
| VCL Number | Machine Type | CPU Make/Model | RAM | Disk | NICs | Remote Control? | PCI | Quantity |
|---|---|---|---|---|---|---|---|---|
| 1 | SuperMicro Blade | AMD Opteron 2473E (2 x quad-core) | 8GB DDR2 800/667/533MHz buffered/registered, | 150GB 10K RPM SATA II | 2 Intel 82571EB | Yes, via IPMI AOC-SIMBL | PCI 2.2 (no expansion) | 10 |
| 2 | Dell Optiplex 7040 | Intel i7-6700 CPU 3.40GHz 4c/8t 65W | 16GB (2x8GB) 2133Mhz DDR4 | 500GB 7200 RPM SATA | 1 Intel Pro/1000 | maybe vPro | 2 PCI-e x16, 1 PCI-e x1, 1 PCI | 20 |
| 3 | Dell Optiplex 7040 | Intel i7-6700 CPU 3.40GHz 4c/8t 65W | 16GB (2x8GB) 2133Mhz DDR4 | 500GB 7200 RPM SATA | 1 Intel Pro/1000 | maybe vPro | 2 PCI-e x16, 1 PCI-e x1, 1 PCI | 30 |
| 4 | Dell PowerEdge R815 | 4xAMD Opteron 6376 16-core | 256GB (DDR3-1600 ECC Registered) | 2x146GB 15K RPM, 2x300GB 10K RPM, 2x1.2TB 10K RPM | 4 | Yes, via iDRAC 6 Enterprise | 3 PCI-e x16 FH, 1 PCI-e x8 FH, 2 PCI-e x8 LP (low profile) | 7 |
| 5 | MSI A78M-E45 Mainboard | A10-7700K Quad-Core APU Processor 3.4GHz Socket FM2+ | 8GB (DDR3 1866) | 250GB VelociRaptor SATA 10K RPM 3.5" | 1 | No | 2 PCI-e x16, 1 PCI-e x1, 1 PCI-e gen3 x16, 1 PCI | 15 |
| 6 | MSI A78M-E45 Mainboard | A10-7700K Quad-Core APU Processor 3.4GHz Socket FM2+ | 8GB (DDR3 1866) | 250GB VelociRaptor SATA 10K RPM 3.5" | 1 | No | 2 PCI-e x16, 1 PCI-e x1, 1 PCI-e gen3 x16, 1 PCI | 12 |
| 7 | MSI A78M-E45 Mainboard | A10-7700K Quad-Core APU Processor 3.4GHz Socket FM2+ | 8GB (DDR3 1866) | 250GB VelociRaptor SATA 10K RPM 3.5" | 1 | No | 2 PCI-e x16, 1 PCI-e x1, 1 PCI-e gen3 x16, 1 PCI | 10 |
| 8 | Dell PowerEdge R410 | 2xIntel Xeon E5520@2.27GHz 4-core or 2xIntel Xeon X5650@2.67GHz 6-core | 32GB (DDR3 1333) | 1x250GB SATA or 1x450GB SATA | 2 | Yes, via iDRAC 6 Enterprise (10 servers have it) | ? | 17 |
| 9.1..17 | ASRock Fatal1ty X399 | AMD Ryzen Threadripper 2920X 12-Core, 24-Thread, 3.5/4.3GHz 180W | 32GB (DDR4 2133) | 1 TB NVME SSD | 1 10Gb Aquantia, 2xIntel 1Gb | No | 4 PCIe 3.0 x16, 1 PCIe 2.0 x1 | 17 |
| 9.18..34 | ASRock Fatal1ty X399 | AMD Ryzen Threadripper 2950X 16-Core, 32-Thread, 3.5/4.4GHz 180W | 64GB (DDR4 2666) | 1 TB NVME SSD | 1 10Gb Aquantia, 2xIntel 1Gb | No, but Web Power Switch on cn31..34; second WPS is currently inactive | 4 PCIe 3.0 x16, 1 PCIe 2.0 x1 | 17 |
| 10 | ASRock X399 Taichi | AMD Ryzen Threadripper 1950X 16-Core, 32-Thread, 3.4GHz 180W | 32GB (DDR4 2400) | 1TB HD, 512GB NVME SSD | 2xIntel 1Gb | No | 4 PCIe 3.0 x16, 1 PCIe 2.0 x1 | 5 |
| 11 | Dell Optiplex 5055 | AMD Ryzen 5 Pro 1600, 6-Core, 12-Thread, 3.2/3.6GHz 65W | 20GB (DDR4 2666) | 512GB or 1TB NVME SSD | 1Gb | No, but maybe vPro? | 1 PCIe 3.0 x16 | 61 |
| 12a | AsRock TRX40 Creator | AMD Ryzen Threadripper 3990X, 64-Core, 128-Thread, 3.9/4.3GHz 280W | 256GB (DDR4 3200) | 1TB (Rocket) and 2TB (Firecuda 520) NVME 4.0 SSDs | 1Gb, 10Gb | No, but screen access via CP 206N Spider Duo and power control via Web Power Switch | 4 PCIe 4.0 x16 | 6 |
| 12b | PowerEdge R6525 | AMD EPYC 2x7H12, 64-Core (per CPU), 128-Thread (per CPU), 2.6/3.3GHz 280W | 512GB (DDR4 3200) | 3.84TB Read-intensive 7008TBW SAS SSD, 3.84TB Multi-use 21024TBW SAS SSD | 1Gb LOM, 10Gb(?) | Yes, via iDRAC Enterprise 9 | PCIe 4.0 x16 | 2 |
Intelligent Platform Management Interface (IPMI) provides a means of remotely managing a system. IPMI-capable VCLs are more configurable than the non-IPMI-capable VCLs because each compute node has remote management hardware that allows powering up or down the node and viewing the console as the system powers up or down. Some VCLs, such as the blades, also allow attachment of virtual media to install software on the bare metal. Whereas compute nodes can be bare-metal imaged via the Apache VCL project's management software, users won't be able to do that remotely without IPMI.
Via the reservation system, users specify what they want, and the provisioning system determines an available compute node, loads any desired images and/or applications onto that node and monitors the progress of the loading, and then notifies the reservation system that the compute node is ready.
The user connects to the compute node or VM running on the compute node via remote display software, performs their work, is notified of the time remaining in the reservation, and then exits or is kicked off the node after the reserved time is up.
The loaded computing environment is either saved or discarded, and then deleted from the compute node.
A compute node is expected to be either bare metal, or run Fedora x86_64 with VirtualBox managing the virtual machines. Subject to licensing restrictions, we may also run Windows directly on the bare metal. We may support other hypervisors in the future.
Management nodes provide the reservation system and the provisioning system.
There are two management nodes per VCL for redundancy and performance. They share a glusterfs-controlled storage cloud of their own, where each node replicates to the other's /home/rw directory. The replicated storage holds a MySQL database and all VM images. The installed software is almost identical on both nodes, with some changes in configuration for node names, IP addresses, and glusterfs volume specifications.
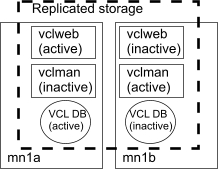
One management node runs a VM ("vclweb") which has a public IP address and provides the web interface that the users see as the reservation system. The node hosting vclweb also runs MySQL server natively. The other management node runs a VM ("vclman") which has a private IP address and does the provisioning by consulting the database remotely and updating it as needed to maintain the state of the provisioning. vclman is on its own node for better performance and for the possibility of scaling up to multiple provisioning nodes.
If one management node goes down, the other can be manually configured to take over:
MySQL can be brought up, configuration changes can be made to point the web server to the correct database server, the external IP address can be set, and the vclweb VM can be started.
The IP address for vclman can be changed, and the vclman VM can be started.
A management node is an AsRock A780GMH mainboard with an Athlon X2 5050E processor, 2x2GB RAM and 500GB SATA II drive. It is intended to run Fedora x86_64, BIND (Berkeley Internet Name Daemon) glusterfs, VirtualBox, MySQL, and xCAT, but since Summer 2011 it is only running BIND. It is also intended to run a Fedora mirror, so the storage nodes can find updates locally, since they are on a private subnet.
The reservation system comes from the Apache VCL project, which is the open source version of the North Carolina State University VCL system, upon which the idea for our VCL and its software is based. We are trying to use as much of their system as possible to avoid the cost of maintaining software specific to our installation. They are in the process of upgrading the software and removing any licensing restrictions from it, so it is more "bleeding edge" than we would want, but since the alternative is re-inventing the wheel, we decided to go with accepting the problems they have versus the ones we would create, and maybe be able to contribute to the project as well.
Our reservation system is composed of a VM called "vclman" and a database called "vcl". vclman provides a web-based interface to the VCL.
The reservation system allows users to reserve a computing environment, but it also allows users with the appropriate access to be able to define the computers and other resources and to create and modify groups for easier management. Information is placed in the database and some of it is subsequently processed by the provisioning system.
The provisioning system consists primarily of xCAT, an open source cluster administration toolkit, originally designed for managing nodes in a compute cluster for high-performance computing. It is a collection of perl scripts and Unix tools that are tailored for this task.
Apache VCL 2.2.1 supports VirtualBox as well as VMware.
The immediate plans for our VCL do not require the bare-metal imaging for which xCAT is famous, but VM image control and other tool support make it useful for our immediate needs, if everything can be made to work well by the time we need it. If not, we will have to manually provision the machines.
xCAT needs to know information in the vcl database and be able to update its progress in that database. It also needs to know about our storage cloud, since the images are stored there. We anticipate needing to write a small number of custom scripts to do what we need to do for our environment, since the NCSU VCL puts the burden of saving an image on the user, not on the VCL system. We don't do that since we think there will be far too much data transfers going on as it is without having the users performing transfers, and there is no good way of providing the users with a way to download their images.
Even though the disks are replicated, we intend to have a backup disk attached to the network ( Network Direct-Attached Storage (NDAS)) that should be at least as large as the non-replicated storage on the system. Since each storage node has 300GB of read-write storage, and there are four such nodes (replicated to four other nodes, but we don't back up twice), that's 1.2TB of storage. Current backup disks are 1.5TB disks, so this should be enough to hold a copy of all of the data, and 3TB disks can be purchased if need be as of Summer 2012.
But how does one get all that data to the backup disk? For one thing, the disk also needs to be attached to a computer because it can't be shared by multiple computers (yet, from Linux -- Windows can). The plan is for the management node that runs vclman will also perform an rsync from the storage cloud to the backup disk.
The backup disk will be removed once per week and stored in another building, for disaster recovery. A similar backup disk will be put on the network for the next week. There will need to be some means of knowing what files are already on the archived backup disk so we don't write everything on the newly-added backup disk as soon as it is added -- we only want the deltas for that week on it.